 INSPIRE-1
INSPIRE-1
Creation year
2021
128396 record(s)
Provided by
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Update frequencies
Service types
-
INSPIRE View Service for Digital Terrain Model Grid Width 200 m (DGM200). The Digital Terrain Model DGM200 describes the terrain forms of the earth’s surface by means of a point quantity arranged in a regular grid, which is georeferenced to planimetry and altimetry. The grid width is 200 m. The data provided through this service covers the area of Germany. Ground resolution: 200m
-

The World Settlement Footprint WSF 2015 version 2 (WSF2015 v2) is a 10m resolution binary mask outlining the extent of human settlements globally for the year 2015. Specifically, the WSF2015 v2 is a pilot product generated by combining multiple datasets, namely: • The WSF2015 v1 derived at 10m spatial resolution by means of 2014-2015 multitemporal Landsat-8 and Sentinel-1 imagery (of which ~217K and ~107K scenes have been processed, respectively); https://doi.org/10.1038/s41597-020-00580-5 • The High Resolution Settlement Layer (HRSL) generated by the Connectivity Lab team at Facebook through the employment of 2016 DigitalGlobe VHR satellite imagery and publicly released at 30m spatial resolution for 214 countries; https://arxiv.org/pdf/1712.05839.pdf • The novel WSF2019 v1 derived at 10m spatial resolution by means of 2019 multitemporal Sentinel-1 and Sentinel-2 imagery (of which ~ 1.2M and ~1.8M scenes have been processed, respectively); https://doi.org/10.1553/giscience2021_01_s33 The WSF2015 v1 demonstrated to be highly accurate, outperforming all similar existing global layers; however, the use of Landsat imagery prevented a proper detection of very small structures, mostly due to their reduced scale. Based on an extensive qualitative assessment, wherever available the HRSL layer shows instead a systematic underestimation of larger settlements, whereas it proves particularly effective in identifying smaller clusters of buildings down to single houses, thanks to the employment of 2016 VHR imagery. The WSF2015v v2 has been then generated by: i) merging the WSF2015 v1 and HRSL (after resampling to 10m resolution and disregarding the population density information attached); and ii) masking the outcome by means of the WSF2019 product, which exhibits even higher detail and accuracy, also thanks to the use of Sentinel-2 data and the proper employment of state-of-the-art ancillary datasets (which allowed, for instance, to effectively mask out all roads globally from motorways to residential).
-

Compilation of the European Quaternary marine geology (section of Germany). The original map consists of data at highest available spatial resolution, map scale („multi-resolution“-concept) and data completeness vary depending on the project partner (as of 2019 April). Project partners are the national geological services of the participating countries. According to the Data Specification on Geology (D2.8.II.4_v3.0) the geological map (section of Germany) provides INSPIRE-compliant data. The WMS EMODnet-DE Quaternary (INSPIRE) contains layers of the geologic units (GE.GeologicUnit) displayed correspondingly to the INSPIRE portrayal rules. The geologic units are represented graphically by stratigraphy (GE.GeologicUnit.AgeOfRocks) and lithology (GE.GeologicUnit.Lithology). The portrayal of the lithology is defined by the first named rock. Via the getFeatureInfo request the user obtains detailed information on the lithology, stratigraphy (age) and genesis (event environment and event process).
-
Compilation of the European Quaternary marine geology (section of Germany). The map consists of data at highest available spatial resolution, map scale („multi-resolution“-concept) and data completeness vary depending on the project partner (as of 2019 April). Project partners are the national geological services of the participating countries. According to the Data Specification on Geology (D2.8.II.4_v3.0) the content of the geological map is stored in a INSPIRE-compliant GML file: EMODnet-DE_Quaternary_GeologicUnit.gml contains the geologic units. The GML file together with a Readme.txt file are provided in ZIP format (EMODnet-DE_Quaternary-INSPIRE.zip). The Readme.text file (German/English) contains detailed information on the GML file content. Data transformation was proceeded by using the INSPIRE Solution Pack for FME according to the INSPIRE requirements.
-
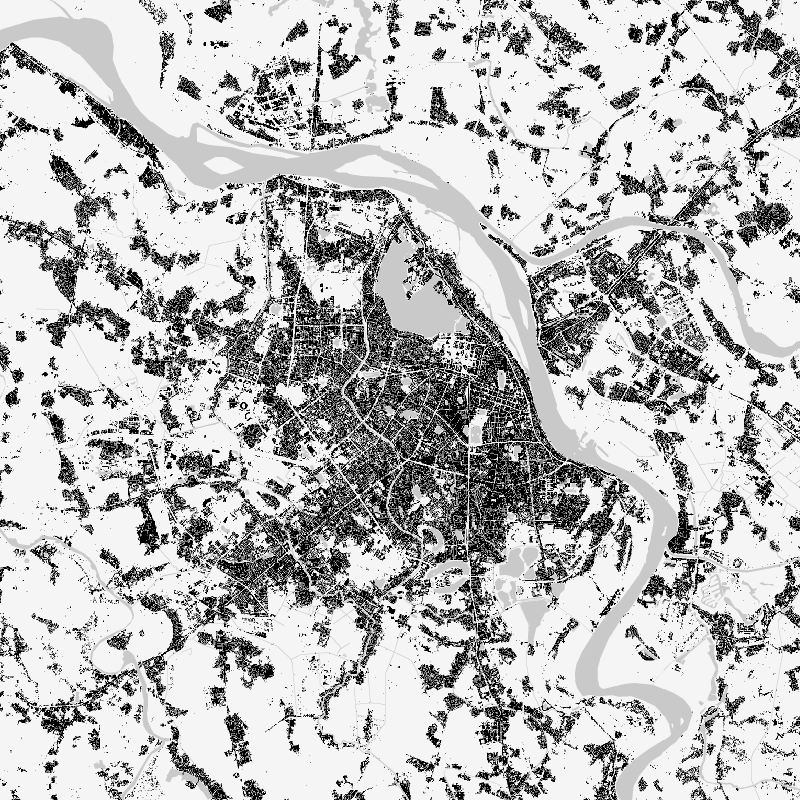
The World Settlement Footprint (WSF) 2019 is a 10m resolution binary mask outlining the extent of human settlements globally derived by means of 2019 multitemporal Sentinel-1 (S1) and Sentinel-2 (S2) imagery. Based on the hypothesis that settlements generally show a more stable behavior with respect to most land-cover classes, temporal statistics are calculated for both S1- and S2-based indices. In particular, a comprehensive analysis has been performed by exploiting a number of reference building outlines to identify the most suitable set of temporal features (ultimately including 6 from S1 and 25 from S2). Training points for the settlement and non-settlement class are then generated by thresholding specific features, which varies depending on the 30 climate types of the well-established Köppen Geiger scheme. Next, binary classification based on Random Forest is applied and, finally, a dedicated post-processing is performed where ancillary datasets are employed to further reduce omission and commission errors. Here, the whole classification process has been entirely carried out within the Google Earth Engine platform. To assess the high accuracy and reliability of the WSF2019, two independent crowd-sourcing-based validation exercises have been carried out with the support of Google and Mapswipe, respectively, where overall 1M reference labels have been collected based photointerpretation of very high-resolution optical imagery.
-
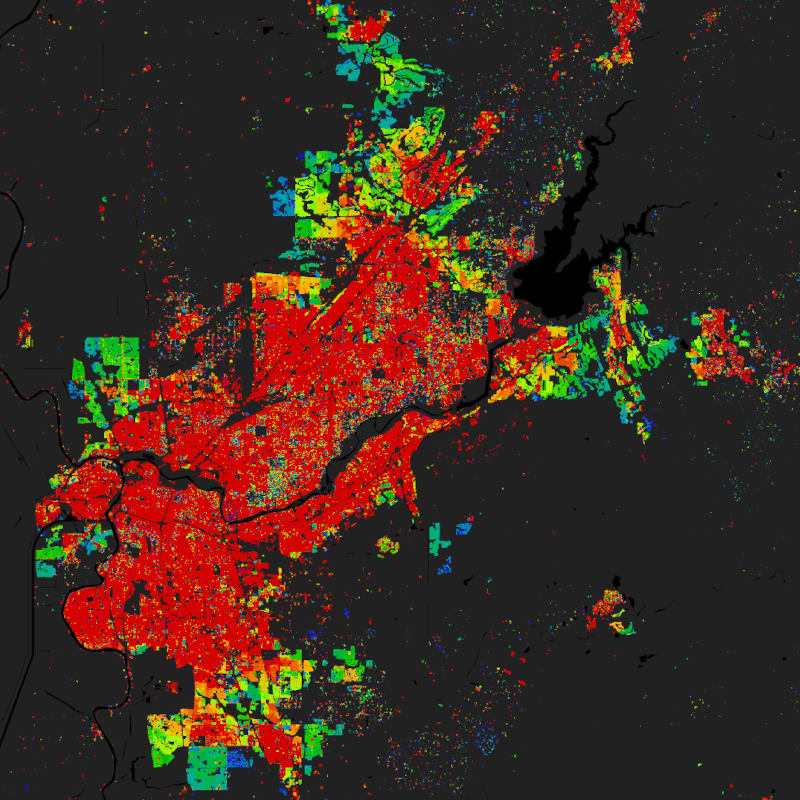
The World Settlement Footprint (WSF) 2019 is a 10m resolution binary mask outlining the extent of human settlements globally derived by means of 2019 multitemporal Sentinel-1 (S1) and Sentinel-2 (S2) imagery. Based on the hypothesis that settlements generally show a more stable behavior with respect to most land-cover classes, temporal statistics are calculated for both S1- and S2-based indices. In particular, a comprehensive analysis has been performed by exploiting a number of reference building outlines to identify the most suitable set of temporal features (ultimately including 6 from S1 and 25 from S2). Training points for the settlement and non-settlement class are then generated by thresholding specific features, which varies depending on the 30 climate types of the well-established Köppen Geiger scheme. Next, binary classification based on Random Forest is applied and, finally, a dedicated post-processing is performed where ancillary datasets are employed to further reduce omission and commission errors. Here, the whole classification process has been entirely carried out within the Google Earth Engine platform. To assess the high accuracy and reliability of the WSF2019, two independent crowd-sourcing-based validation exercises have been carried out with the support of Google and Mapswipe, respectively, where overall 1M reference labels have been collected based photointerpretation of very high-resolution optical imagery. Starting backwards from the year 2015 - for which the WSF2015 is used as a reference - settlement and non-settlement training samples for the given target year t are iteratively extracted by applying morphological filtering to the settlement mask derived for the year t+1, as well as excluding potentially mislabeled samples by adaptively thresholding the temporal mean NDBI, MNDWI and NDVI. Finally, binary Random Forest classification in performed. To quantitatively assess the high accuracy and reliability of the dataset, an extensive campaign based on crowdsourcing photointerpretation of very high-resolution airborne and satellite historical imagery has been performed with the support of Google. In particular, for the years 1990, 1995, 2000, 2005, 2010 and 2015, ~200K reference cells of 30x30m size distributed over 100 sites around the world have been labelled, hence summing up to overall ~1.2M validation samples. It is worth noting that past Landsat-5/7 availability considerably varies across the world and over time. Independently from the implemented approach, this might then result in a lower quality of the final product where few/no scenes have been collected. Accordingly, to provide the users with a suitable and intuitive measure that accounts for the goodness of the Landsat imagery, we conceived the Input Data Consistency (IDC) score, which ranges from 6 to 1 with: 6) very good; 5) good; 4) fair; 3) moderate; 2) low; 1) very low. The IDC score is available on a yearly basis between 1985 and 2015 and supports a proper interpretation of the WSF evolution product. The WSF evolution and IDC score datasets are organized in 5138 GeoTIFF files (EPSG4326 projection) each one referring to a portion of 2x2 degree size (~222x222km) on the ground. WSF evolution values range between 1985 and 2015 corresponding to the estimated year of settlement detection, whereas 0 is no data. A comprehensive publication with all technical details and accuracy figures is currently being finalized. For the time being, please refer to Marconcini et al,. 2021.
-

Since the end of the 1980ies the geological, areal and production data of operating mining sites have been collected systematically by LGRB. The periodic update of this information is carried out every four or five years. Main reasons are 1) the preparation of the periodic follow-up of the 12 regional development plans, 2) the work on the near-surface mineral raw material maps published by LGRB, and 3) the periodical editing of the state report for near-surface mineral raw materials published by LGRB at the start of each new election period. The geological data include a detailed documentation of the thickness, petrography and quality of mined rock(s) and the overburden as well as geochemical data gained from rock samples. The areal data refer both to the permitted mining area (zones of recultivation, work and expansion) and to possible areas for the mine expansion (the latter are confidential). Due to the quick spatiotemporal variability of these data, here all mining sites are shown as point data. The confidential annual production data are the basis for the periodic raw material report. In addition, another data are collected, e.g. for the mining permission, the delivery area and the subsequent land use. All these data are stored in the mining site database of the LGRB (Rohstoffgewinnungs-stellendatenbank = RGDB). This one comprises also the data for abandoned mining sites and mines. In total, actual (2021) about 14.000 data records are stored. The name of each mining site (e.g. RG 6826-3) consists of three parts. RG is the abbreviation for "Rohstoffgewinnungsstelle". the following four-digit number means the number of the relevant topographic map 1 : 25.000. The last number means the serial number of the mining site; serial numbers 1-99 mark operating mining sites gathered since the end of the 1980ies ( (today partially already closed) , such > 100 mark abandoned mining sites collected before 1980 and such > 300 mark data of mining sites and mines collected in the course of actual raw material mapping. The mintell4eu data set comprises all mining sites with serial numbers 1-99. In addition, the most important abandoned mines of former or probably still ongoing economic importance.
-

Since 1999, the Geologic Survey of Baden-Württemberg publishes a statewide geological map series 1 : 50 000 "Karte der mineralischen Rohstoffe 1 : 50 000 (KMR 50)". On it, the distribution of near-surface mineral raw material prospects and occurrences (mainly) and deposits (subordinate) is shown. This continuously completed and updated map currently covers around 60% of the federal state. It is the base for the regional associations in the task of mineral planning. The prospects and occurrences are classified according to different raw material groups (e.g. raw material for crushed stone (limestone, igneous rocks, metamorphic rocks, sand and gravel), raw materials for cement, dimension stone, high purity limestone, gypsum ...). Their spatial delineation is based on various group-specific criteria such as minimum workable thickness, minimum resources, ratio overburden/workable thickness, and so on. It is assumed that they contain deposits as a whole or in parts. In the vast majority of cases, the data is not sufficient for the immediate planning of mining projects, but it does facilitate the selection of exploration areas. The name of each area (e.g. L 6926-3) consists of three parts. L = roman rnumeral fo 50, 6926 = sheet number of the topographic map 1 : 50 000, 3 = number of the area/mineral occurrence shown on this sheet. Co-occurring land-use conflicts, e.g. water protection areas and nature conservation areas, forestry and agriculture, are not taken into account in the processing of KMR 50. Their assessment is the task of land use planning, the licensing authorities and the companies interested in mining. The data is stored in the statewide raw material area database "olan-db" of the LGRB.
-

Compilation of the European Pre-Quaternary marine geology (section of Germany). Project partners are the national geological services of the participating countries. The map consists of data at highest available spatial resolution, map scale („multi-resolution“-concept) and data completeness vary depending on the project partner (as of 2016 September). According to the Data Specification on Geology (D2.8.II.4_v3.0) the content of the geological map is stored in a INSPIRE-compliant GML file: EMODnet-DE_Pre-Quaternary_GeologicUnit.gml contains the geologic units. The GML files together with a Readme.txt file are provided in ZIP format (EMODnet-DE_Pre-Quaternary-INSPIRE.zip). The Readme.text file (German/English) contains detailed information on the GML file content. Data transformation was proceeded by using the INSPIRE Solution Pack for FME according to the INSPIRE requirements.
-
Darstellungsdienst (WMS)